前回のSkillsの「裏方」を作った話...ポートフォリオMCPサーバー
株式ポートフォリオをAIで分析する
株式ポートフォリオをAIで分析する
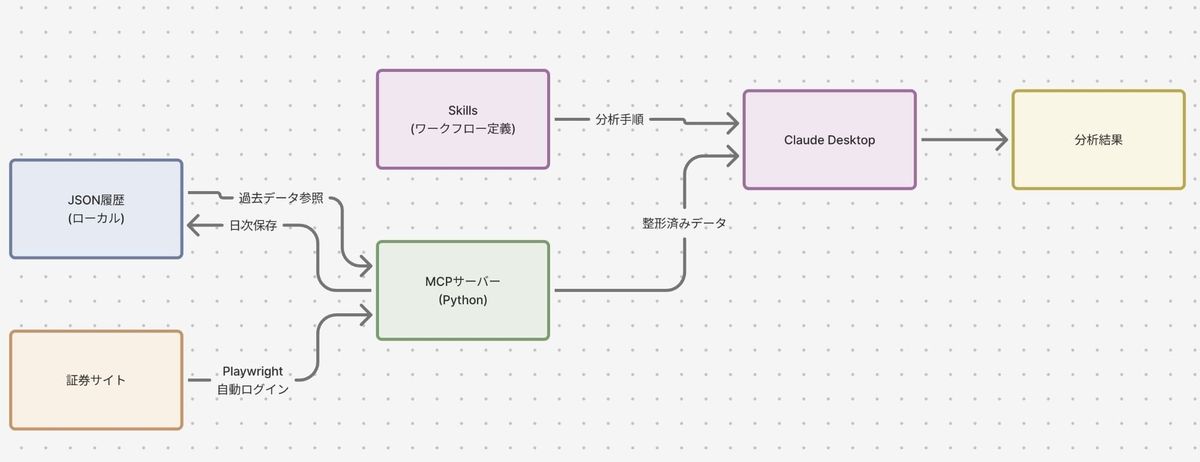
前回の記事では、保有株の分析・売買判断をClaudeのSkillsで手順化した話を書いた。「料理で言えばMCPサーバーが食材の仕入れ担当、Skillがレシピと品質基準書」と比喩したが、今回はその仕入れ担当の中身の話をする。
証券口座の保有データを自動取得し、履歴を蓄積し、整形してClaudeに渡す——MCPサーバーをどう設計し、どう作り、どう運用しているか。
なぜ「仕入れ」を自動化する必要があったか
本来はAPIでデータを取得したかった。だが日本のネット証券の多くは、個人向けにポートフォリオ取得用のAPIを公開していない。保有状況を確認するには、手動でログインして画面を見るしかない。
であれば、そのログインとデータ取得をプログラムで再現するしかない——Playwrightでヘッドレスブラウザを動かすという、やや力技の選択はそこから来ている。
加えて、Skillsで分析の質を上げても、入力データの準備が手作業のままではボトルネックになる。画面からコピーした数値はフォーマットが揃わないし、過去データとの比較をしたくても先週のスクリーンショットを探すところから始まる。MCPサーバーは、この「APIがないなら自分で作る」という発想から生まれた。
MCPサーバーの構成
MCP(Model Context Protocol)は、AIに外部ツールを接続する仕組みだ。今回のサーバーはPython製で、内部でPlaywright(ヘッドレスブラウザ)を動かし、証券口座に自動ログインしてデータを取得する。
サーバーがClaudeに公開するツールは以下のようなものがある。
| ツール | 機能 |
|---|---|
fetch_portfolio |
現在の保有状況を全口座分取得 |
get_historical_data |
指定日の過去スナップショットを返す |
analyze_with_ai |
蓄積データをもとに分析を実行 |
ポイントは、取得したデータをその場で返すだけでなく、ローカルにJSON形式で日次蓄積していることだ。これがあるから「先月と比べてどう変わった」という問いに答えられる。
返却データの構造はこんな形になる(※架空のサンプル)。
{
"account_type": "特定",
"ticker": "1234",
"name": "○○高配当ETF",
"quantity": 500,
"avg_cost": 2100.0,
"current_price": 2050.0,
"unrealized_pnl_pct": -2.38
}
AIはこの整形済みデータを受け取る。HTMLのパースに失敗するとか、ログインセッションが切れるとか、そういう問題はMCPサーバー側で完結する。Claudeは「綺麗なデータが来る」とだけ思っていればいい。
Skillsと組み合わせるとこうなる
前回のSkillsと今回のMCPサーバーが合わさると、実際にはこんなやり取りになる(※ダミーデータによる再現)。
「ポートフォリオを分析して」と指示すると、Claudeはまず fetch_portfolio を呼んで現在のデータを取り、get_historical_data で過去数日分を取得する。ここまでがMCPの仕事だ。
その上で、Skillsに定義されたワークフロー——市場環境の調査、比較テーブルの作成、判断品質マトリクスの適用——に沿って分析が走る。
取得データ例:
特定口座:
○○高配当ETF(1234) 500株 取得2,100円 → 現在2,050円 ▲2.4%
△△金ETF(5678) 200株 取得8,500円 → 現在12,300円 +44.7%
NISA口座:
□□全世界株ETF(9012) 80株 取得2,800円 → 現在3,200円 +14.3%
現金:180万円
Claudeの分析(要旨):
- 高配当ETFは含み損だが配当利回り3.8%。インカム目的なら保有継続が合理的
- 金ETFは+44.7%。地政学リスク継続中のためヘッジとして保持
- 現金比率18%。現環境では適切
- 前月比:配当利回り加重平均が3.1%→3.3%に上昇
分析の具体例:実際はもっと詳細で詳しい
最後の「前月比」は、日次蓄積された過去データがなければ出せない。MCPサーバーが仕入れた食材をSkillsのレシピで調理する、という構造がここで繋がる。
セキュリティの設計
個人の金融データを扱うので、ここは慎重に設計した。
認証情報は .env ファイル経由でローカルに完結する。外部の家計簿SaaSに証券口座のログイン情報を預ける必要はない。
AIへのデータ送信については、Anthropic APIの場合、送信データはデフォルトでモデル学習に使用されない。ただしこれはベンダーごとにポリシーが異なるので、他のLLMを使う場合は各社の規約を確認してほしい。
MCPの構造上、データは「自分がプロンプトで指示したタイミング」でしか送信されない。常時接続でデータが抜かれる仕組みとは根本的に異なる。
構築はAIエージェントとの対話で
Playwrightでのスクレイピング、日次蓄積、MCPプロトコル準拠のサーバー実装。重そうに見えるが、大部分はAntigravity(AIコーディングエージェント)やClaude Codeとの対話で構築した。
「この画面からポートフォリオの数値を取りたい」「JSONで日次保存して」「過去比較のツールを追加して」——こうした指示を出すと、エージェントがコードを書き依存関係を整理する。人間はデータフローの設計に注力できた。
ハマったところ
- セッション管理:二段階認証が絡むと自動ログインが不安定になる。Cookie保持で対処しているが、定期的に切れるのでエラーハンドリングは入念に作った
- MCPのデバッグ:ホストアプリから呼ばれる構造なので単体テストがやりにくい。
stderrログとテスト用クライアントで地道に対処した - HTML構造変更:証券サイトのUI改修で突然スクレイピングが壊れる。保守コストはゼロではない
運用構成
日常の流れはこうだ。
- MacBookでClaude Desktopを起動
- 「ポートフォリオを分析して」とか「本日の中東の状況を踏まえて私のポートフォリオに与えるインパクトを分析して」などと入力
- ローカルのMCPサーバーが証券サイトからデータ取得→整形→Claudeに返却
- Skillsのワークフローに沿って分析が返る
MCPサーバーはMacBook上で直接動いている。claude_desktop_config.json にサーバーの起動コマンドを書くだけで、Claude Desktopが自動的にプロセスを立ち上げてくれる。
なお、Playwrightの実行環境を手元のマシンに置きたくない場合は、自宅のデスクトップやサーバーでMCPを動かし、SSH経由で呼び出す構成も可能だ。MCPの仕組み上、command にSSHを指定するだけで対応できる。
注意事項
本記事のスクレイピングは自身の口座情報を個人利用の範囲で取得するものであり、自動売買やサービス提供を目的としていない。証券サイトへのスクレイピングは利用規約で制限される場合がある。アクセス頻度を抑える等の配慮をお願いしたい。
まとめ
前回は「AIに渡すレシピ(Skills)」の話だった。今回は「食材の仕入れ(MCPサーバー)」の話だ。
パスワードはローカルに留め、泥臭いスクレイピングと蓄積はMCPに任せ、整ったデータだけをAIに渡す。この構成をAIエージェントとのペアプロで組み上げた。
今後の課題は保守性だ。証券サイトのUI改修でスクレイピングが突然壊れたとき、構造変更を自動検知してセレクタの修正案まで生成する仕組みを作りたい。前回のSkillsと合わせて、「AIとの協業基盤」が少しずつ形になってきている。


Comments ()